Right after migrating all my images onto Cloudinary I started to question myself: how am I going to make backups?
Nothing lasts forever, including clouds. Or, for example, one day you can lose your Cloudinary account and hence your access to the hosting altogether. Therefore the task of making a copy of your content is quite relevant.
Paid Cloudinary plans offer the function of backing up into an Amazon S3 bucket. This feature is, however, not available on their free plan.
Backup script
I didn’t have a minute doubt it would be easy to write an automated backup script, given the variety of APIs Cloudinary provides.
And indeed, it cost me less than an hour to write a snappy Python program that downloads all images and videos onto your local drive. Meet cloudinary-backup!
Getting started
In order to use the script:
- Install the “cloudinary” package by running
sudo pip3 install cloudinary. - Export the
CLOUDINARY_URLenvironment variable to becloudinary://<api_key>:<api_secret>@<cloud_name>. This value can be easily copied in your Cloudinary Dashboard. - Adjust the
BACKUP_DIRvariable in the script's header to point to the desired local folder.
Running
Once the above is done, the script can be simply run (you can use the -v command-line option to get more verbose output):
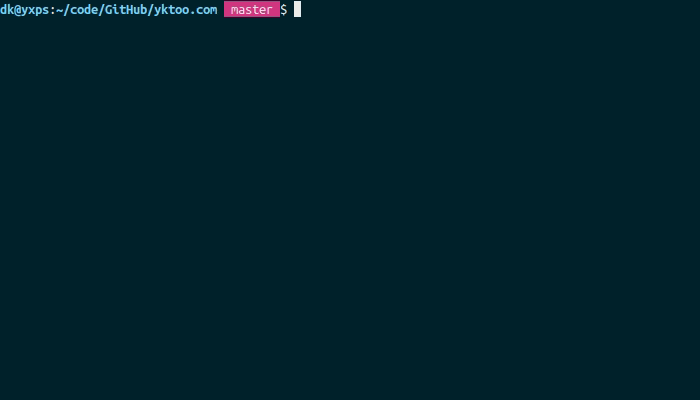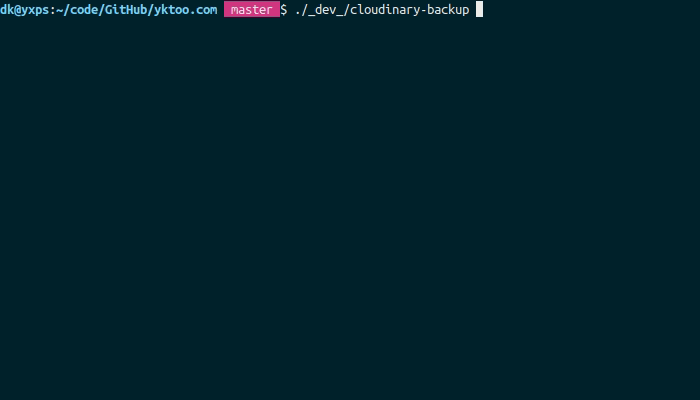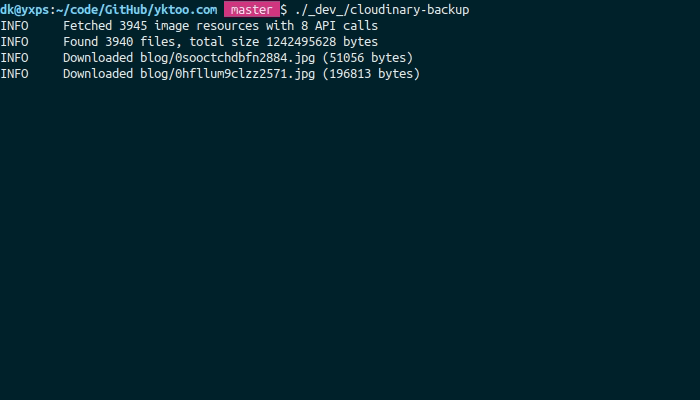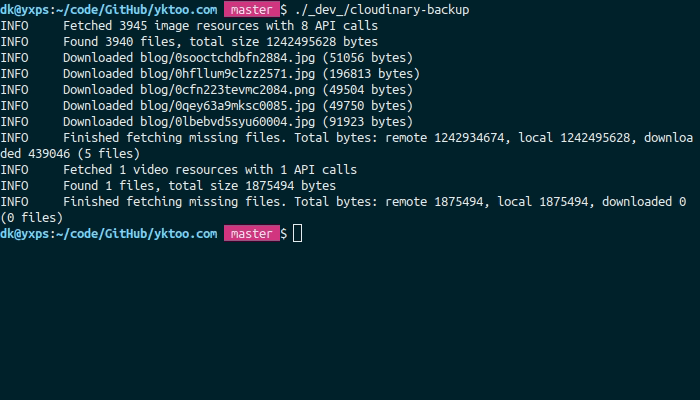
The program compares the cloud content with its local version and downloads only those files that are either missing or differ in size.
One thing worth mentioning here is that the Admin API, which is used to retrieve resource lists, is rate-limited.
On the other hand, the limit is set at 500 requests per hour, and each request can fetch up to 500 items, which means if you host less than 250 K files, you’re probably fine.
Removing redundant files
If the program is started with the -d command line switch, local files that aren’t present in Cloudinary will be automatically cleaned up.
Source code
The source code of the script is available on GitHub.
Comments